
sábado, 30 de abril de 2016
Viaje a Huelva
En el día de ayer, mis compañeras Andrea, Irene, Concha y yo nos fuimos a Huelva para realizar las encuestas necesarias para el trabajo de investigación. Las encuestas se las hicimos a las mujeres gestantes y a las que hayan dado a luz alguna vez en su vida, ya que os adelanto que nuestra temática seleccionada ha sido la información, mitos y conocimientos que les proporcionan el personal sanitario con respecto al embarazo.
Nos sorprendimos con muchas de las respuestas y tuvimos más de una anécdota que próximamente os contaré.
Aquí os dejo una foto en el viaje de ida...

miércoles, 27 de abril de 2016
EJEMPLOS DE PROBLEMAS
Buenas!! En la clase del día de ayer estuvimos haciendo problemas y aquí os dejo algunos ejemplos:
1. Un grupo de enfermera realiza un
estudio para conocer la frecuencia de lesiones causados por los sistemas de
extracción de sangre por vacio. Para ello una muestra de 150 pacientes se recoge
datos de las lesiones ocasionadas ayándose un total de 20 pacientes con
lesiones. Se pide que calcule el intervalo
de confianza de la frecuencia de lesiones por extracciones por vacio, del 95 y
99%.
N:150 ICP= P +- Z
) P=
Lesionados:20 p=20/150:0.13
Confianza
al 95% y 99%. ICP=0.13+1.96*
ICP95%=0.13+-1.96*0.03
ICP95%=0.13+-0.06
ICP95%=0.13+0.06=0.18
ICP95%=0.13-0.06=0.08 ICP95%=[8%-18%]
ICP99%=0.13+-2.58*0.03
ICP99%= [5%-21%]
2.En una investigación
sobre la obesidad en la población femenina adscrita en el centro de salud se
obtiene un resultado sobre una muestra representativa de 233 mujeres que el
peso medio de la muestra es de 69.6 kg. Y su desviación típica es de 9.8. Se
pide que se calcule el intervalo de confianza de la media del peso en toda la
población adulta femenina adscrita al centro de salud para un 95 y 99 % de
confianza.
N:233
S: 9.8
Media: 69.6
E=s/
e=9.8/
= 0.6
IC95%= 69.6+-1.96*0.6= 69.6+1.25=70.7
69.6-1.25=68.43 IC=[68.43-70.7%]
IC99%= 69.6 +- 2.58* 0.6 =
69.6+1.65=71.25
69.6-1.65= 67.9 IC=
[67.9-71.25%]

domingo, 24 de abril de 2016

viernes, 22 de abril de 2016
INTERVALO DE CONFIANZA
¿Tenéis idea de que es el intervalo de confianza? En primer lugar, se trata de un par de números tales
que, con un nivel de confianza determinados, podamos asegurar que el valor del
parámetro es mayor o menor que ambos números y en segundo lugar, se calcula considerando que el
estimador muestral sigue una distribución normal, como establece la teoría
central del límite.
La formula que acompaña al I.C es esta:

La técnica de muestreo, es un método tal que al escoger un grupo pequeño de una población podamos tener un grado de probabilidad de que ese pequeño grupo posea las características de la población que estamos estudiando.Tipos de muestreo:

El tamaño de la muestra a tomar va a depender del error estándar.

La formula que acompaña al I.C es esta:
La técnica de muestreo, es un método tal que al escoger un grupo pequeño de una población podamos tener un grado de probabilidad de que ese pequeño grupo posea las características de la población que estamos estudiando.Tipos de muestreo:
El tamaño de la muestra a tomar va a depender del error estándar.
- -De
la mínima diferencia entre los grupos de comparación que se considera
importante en los valores de la variable a estudiar. Más grande debe ser la
muestra para que más pequeño sea el error.
- - De
la variabilidad de la variable a estudiar (varianza en la población).
- - El
tamaño de la población de estudio.
Calculo
del tamaño de una muestra para estimar la media de una población.
ESTADÍSTICA INFERENCIAL
Buenas tardes chicos!! hoy os traigo la estadística inferencial, muestreo y estimación. Allá vamos!!
Cuando planteamos un estudio en el ámbito sanitario para
establecer relaciones entre variables, nuestro interés no suele estar
exclusivamente en los pacientes concretos a los que hemos tenido acceso, sino
más bien en todos los pacientes similares a estos, esto significa inferir.
Ø Al conjunto de pacientes sobre los
que queremos estudiar alguna cuestión (sacar conclusiones) le llamamos población de estudio.
Ø Al conjunto de individuos concretos
que participan en el estudio le denominamos muestra.
Ø Al número de individuos de la muestra
le denominamos tamaño muestral.
Ø Al conjunto de procedimientos
estadísticos que permiten pasar de lo particular, la muestra, a lo general, la
población, le denominamos inferencia
estadística.
Ø Al conjunto de procedimientos que
permiten elegir muestras de tal forma que éstas reflejen las características de
la población le llamamos Técnicas de muestreo,
esto se hace para evitar sesgos.
- Si la muestra se elige por un
procedimiento de azar, se puede evaluar ese error. La técnica de muestreo en
ese caso se denomina muestreo
probabilístico o aleatorio y el error asociado a esa muestra elegida al
azar se llama error aleatorio.
- En los muestreos no probabilísticos (Ej: estudios de conveniencia. Utilizar a los pacientes de mi hospital como muestra), no es posible evaluar el error. En los muestreos probabilísticos, el error aleatorio es inevitable pero es evaluable gracias a las leyes de la probabilidad.
- En los muestreos no probabilísticos (Ej: estudios de conveniencia. Utilizar a los pacientes de mi hospital como muestra), no es posible evaluar el error. En los muestreos probabilísticos, el error aleatorio es inevitable pero es evaluable gracias a las leyes de la probabilidad.
- Cuanto mayor sea el tamaño de la
muestra, favorezco la reducción del error aleatorio por probabilidad.
El error estándar es la
medida que trata de captar la variabilidad de los valores del estimador, mide el grado de variabilidad en los
valores del estimador en las distintas muestras de un determinado tamaño que pudiésemos
tomar de una población y por último, cuanto más pequeño es el error
estándar de un estimador, más nos podemos fiar del valor de una muestra
concreta.
Os preguntareis como se calcula....
- Error estándar para una media :
Os preguntareis como se calcula....
- Error estándar para una media :
-Error estándar para una proporción (frecuencia
relativa):
En el siguiente vídeo os explica el teorema central del límite, espero que os sirva.
-
miércoles, 20 de abril de 2016
Si la vida da un cambio de rumbo conocerás otros lugares que también pueden ser maravillosos.
Aquí os dejo un corto dirigido por Emilio Aragón que se ha hecho viral por el tacto y el optimismo con el que se aborda un problema que afecta a en torno a tres millones de personas en España.
La grabación cuenta la historia de unos padres que esperan ilusionados un hijo, algo que proyectan en forma de viaje, imaginando unas vacaciones idílicas en la playa. Sin embargo, los planes se tuercen.
La enseñanza es que un cambio de destino no implica menores satisfacciones, aunque al principio cueste.
La grabación cuenta la historia de unos padres que esperan ilusionados un hijo, algo que proyectan en forma de viaje, imaginando unas vacaciones idílicas en la playa. Sin embargo, los planes se tuercen.
La enseñanza es que un cambio de destino no implica menores satisfacciones, aunque al principio cueste.
MEDIDAS DE DISPERSIÓN
En la clase del día de ayer estuvimos viendo las distintas medidas de dispersión:
·
Rango o recorrido: Diferencia entre el mayor y el
menor valor de la muestra lXn-X1l (valor absoluto).
·
Desviación media: Media aritmética de las distancias de cada
observación con respecto a la media de la muestra:

· Desviación típica o estándar: Cuantifica el error que cometemos si representamos una muestra únicamente por su media. Esta es la que más se emplea debido a que esta nos da un mayor rango de error.

·
Varianza: Expresa la misma información en
valores cuadráticos:
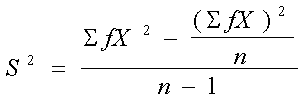
·
Recorrido intercuartílico: Diferencia
entre el tercer y el primer cuartil = lQ3-Q1l
·
Coeficiente de variación: Es
una medida de dispersión relativa (adimensional) ya que todas las demás se
expresan en la unidad de medida de la variable. Nos sirve para comparar la
heterogeneidad de dos series numéricas con independencia de las unidades de
medidas. Se expresa sin unidades.
- c.v.=s/x
También os quiero comentar las distribuciones normales,distribución de
Gauss o distribución gaussiana, a una de las distribuciones de probabilidad de
variable continua que con más frecuencia aparece en fenómenos reales. Es
Distribución de probabilidad más frecuente con variables continuas, por
ejemplo, altura, peso, niveles de colesterol…
Las distribuciones normales en un histograma aparece una
especie de Campana, por eso la campana de Gauss. Y es simétrica respecto de los
valores de posición central, es decir que la moda va a coincidir con la media y
la mediana.
|
Media, moda, mediana.
|

A continuación vimos la simetría y curtosis, cosas que también pudimos observar en el seminario de ayer.

y con respecto a la curtosis:

SEMINARIO 3
Buenos días!!! ayer tuvimos el seminario tres y este seminario se destinó a el aprendizaje de la tercera herramienta, particularmente en el manejo de las herramientas para la realización de un análisis descriptivo de variables , correspondiente a lo siguiente:
- Recodificación de variables.
- Cálculos de medidas de tendencia central y dispersión variables cuantitativas.
- Cálculos de distribuciones de frecuencia y de intervalos de confianza.
- Cálculos y elaboración de gráficas de sectores, diagramas de barras e histogramas.
Estuvimos comentando la simetría:

y la curtosis:

A continuación, cada grupo propusimos cada una de nuestras dudas destinadas al proyecto de investigación.
Más adelante os hablare sobre el proyecto que tenemos pensado mi grupo.
martes, 19 de abril de 2016
LINFOMA DE HODGKIN
En el vídeo publicado anteriormente hay una chica que tiene la enfermedad de Hodgkin, y os preguntaréis que es.
La enfermedad de Hodgkin (linfoma Hodgkin) es un tipo de linfoma, un cáncer que se origina en los glóbulos blancos, llamados linfocitos.
Debido a que el tejido linfático se encuentra en muchas partes del cuerpo, la enfermedad Hodgkin puede originarse en casi todas las partes del cuerpo. Con más frecuencia, se origina en los ganglios linfáticos de la parte superior del cuerpo. Las localizaciones más frecuentes son el tórax, el cuello o debajo de los brazos.
Con más frecuencia, la enfermedad de Hodgkin se propaga por los vasos linfáticos de manera escalonada de ganglio a ganglio. Pocas veces, y en un curso tardío de la enfermedad, puede invadir el torrente sanguíneo y propagarse a otras partes del cuerpo, incluyendo el hígado, los pulmones y/o la médula ósea.
Los diferentes tipos de enfermedad de Hodgkin son clasificados según la apariencia en un microscopio. La clasificación es importante debido a que los tipos de enfermedad de Hodgkin pueden crecer y propagarse de una manera diferente y puede ser tratado de forma distinta. Los dos tipos principales son:
Todos los tipos de enfermedad de Hodgkin son malignos (cancerosos) porque, a medida que crecen, pueden invadir y destruir el tejido normal, e incluso propagarse a otros tejidos.
Una forma diferente de ver la vida
Cuando tuve la oportunidad de este ver este vídeo realmente me cambió el modo de ver la vida.
Espero que a vosotros también os haga sentir lo mismo que a mí.
Un poco más de... bioestadítica
Con respecto a lo que os estaba comentando anteriormente, para la
representación de datos de las variables se suele emplear una tabla de
frecuencia, la cual nos muestra las frecuencias en las columnas (frecuencia
absoluta: fi y la frecuencia relativa: hi) y las
categorías de las variables en las filas.
Recorrido= valor más alto – valor más
bajo= 6.1 -3.3= 2.8
Pero
antes de representar los datos en la tabla primeramente hay que calcular el
recorrido, el intervalo (filas que se cogen para la tabla) y la amplitud. A
continuación lo observaremos en un ejemplo:
Pesos En Kg De Niños
Atendidos En La Consulta De Niño Sano. N = 40
3,9 4,7 3,7 5,6 4,3 4,9 5,0 6,1 5,1 4,5
5,3 3,9 4.3 5.0 6.0 4.7 5.1 4.2 4.4 5.8
3.3 4.3 4.1 5.8 4.4 4.8 6.1 4.3 5.3 4.5
4.0 5.4 3.9 4.7 3.3 4.5 4.7 4.2 4.5 4.8
Intervalo= es la raíz cuadrada del
número total de datos observados= raíz de 40= 6.32
Amplitud=
recorrido/ intervalo= 2.8/6= 0,46
A continuación procedemos a realizar la tabla con los
datos que he detallado en la imagen:
|
Peso en Kg
|
fi(Frecuencia
absoluta)
|
EFi(frecuencia
absoluta acumulada)
|
hi(frecuencia
relativa)
|
Hi (frecuencia
relativa acumulada)
|
|
|
[3.3-3.8]
|
3
|
3
|
0.075 o 7,5%
|
0.075 o 7,5 %
|
|
|
(3.8-4.3]
Mc=4.0
|
8
|
11
|
0.2 o 20%
|
0.275 o 27,5 %
|
|
|
(4,3-4.8]
Mc=4.5
|
14
|
25
|
0.35 o 35%
|
0.625 o 62,5%
|
|
|
(4.8-5.3]
Mc=5.0
|
6
|
31
|
0.15 o 15%
|
0.775 o 77.5%
|
|
|
(5.3-5.8]
Mc=5.5 |
4
|
35
|
0.1 o 10%
|
0.875 o 87,5 %
|
|
|
(5.8-6.3]
Mc=6.0
|
40
|
40 |
100% |
1 o 100% |
A parte de lo dicho anteriormente, también se pueden representar las variables de manera
gráfica, ya que es una forma rápida de transmitir la información numérica,
ofreciendo orientación visual. Podemos distinguir varios tipos de graficas:
·
Diagrama de barras: mide
variables cualitativas, nominales y sobre todo policotómica.
·
Histograma: se
emplea para representar variables continuas.
·
Gráfico de tronco: Para
medir variables cuantitativas continúas.
Cada dato de la serie se divide en dos parte: Tronco a la izquierda
(decenas) y la Hoja a la derecha (unidades).
·
Grafico de sectores: se
utilizan para trabajar con variables cualitativas, preferentemente dicotómicas.
·
Grafico de datos bidimensionales: mide variables cuantitativas.
Suscribirse a:
Comentarios (Atom)